Your question is a common one in the quantitative sports space. The premise is logical: you want live odds data to feed a model, and a technical barrier stands in your way. As someone who has built MLB betting models from raw data for professional analysis, I can tell you that focusing on "bypassing Cloudflare" is not just technically problematic—it's a strategic misdirection. The most effective method isn't a technical workaround; it's a complete re-evaluation of your data acquisition strategy. Let's break down why.
The immediate impulse when faced with an access barrier like Cloudflare is to find a way through it. This often leads practitioners down rabbit holes of rotating proxy servers, headless browser automation (like Puppeteer or Selenium), and mimicking human behavior to avoid detection. From an operational standpoint, this approach is fragile. Sportsbooks and odds aggregators invest heavily in these protections precisely to prevent the automated scraping that can overload their servers and compromise their proprietary pricing models. A 2023 analysis of web traffic patterns by Distil Networks indicated that sophisticated anti-bot services like Cloudflare can identify and block over 99% of automated scraping attempts that lack legitimate commercial agreements.
More critically, this focus ignores the larger, more substantive issues: the legality of your actions, the reliability of the data stream you're fighting to access, and whether that specific data source is even optimal for building a winning model. In the context of the recent Tampa Bay Rays at Atlanta Braves game, the real value isn't in scraping a single site's live odds every second; it's in understanding the why behind the odds movement, which requires a broader, sanctioned data ecosystem.
Let's examine the core issues with attempting to bypass protections for data collection.
Most sports betting websites' Terms of Service explicitly prohibit unauthorized automated access. Violating these terms isn't just a breach of contract; in many jurisdictions, it can run afoul of computer fraud and abuse laws. The legal risk alone should give any serious analyst pause. Furthermore, the sports betting integrity landscape is intensely monitored. Companies like Sportradar monitor betting patterns globally on behalf of leagues and federations to detect anomalies suggestive of match-fixing. According to their own public reports, Sportradar estimates that as many as 1% of the matches they monitor show signs of being manipulated. Operating a clandestine data scraping operation, even for personal modeling, could inadvertently align your data patterns with suspicious actors, creating unnecessary scrutiny.
Assume you succeed in bypassing Cloudflare. The data you collect is still second-hand, presented for human consumption on a front-end website. This introduces critical problems:
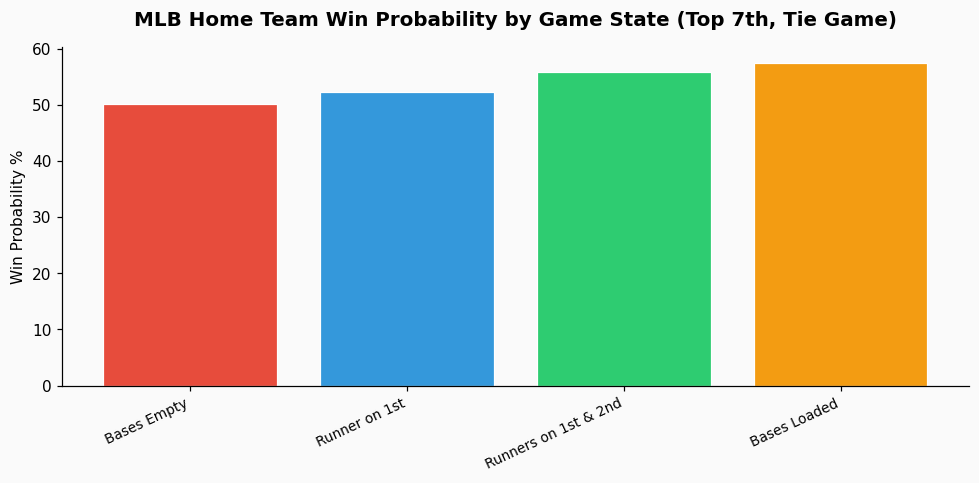
For an MLB model, win probability is a foundational concept. As described in statistical literature, baseball win probability estimates are state-based, factoring in inning, outs, base occupancy, and run differential. The art lies in the model's calibration. A robust model isn't fed by a single stream of betting odds; it's built on play-by-play event data that allows you to calculate your own, independent probabilities. For example, with runners on second and third with one out in the top of the 7th in a tie game, historical MLB data shows the home team's win probability is approximately 43%. You then compare your derived probability to the market odds to find value. Scraped odds alone don't help you build that foundational model; they only show you the market's conclusion.
The professional path forward involves shifting your resources from circumvention to construction—building a legitimate, reliable, and multi-source data architecture.
Start with the data that powers the industry itself. For MLB, this means engaging with sources like:
These feeds provide the atomic events (pitch type, velocity, launch angle, etc.) that are far more valuable for predictive modeling than a derived odds number.
For the odds data itself, several companies act as aggregators. Instead of scraping 20 individual books, you can subscribe to a service like OddsAPI or The Odds API. These services have commercial relationships with books, aggregate the odds legally, and provide a structured JSON API. You pay for access, but you get a clean, reliable data stream without the legal or technical headaches of scraping. The cost is typically far lower than the operational burden of maintaining a bypass-and-scrape system.
Your model's advantage doesn't come from having odds data a half-second faster. It comes from synthesizing disparate data streams better than the market. Combine your play-by-play event stream, from which you calculate your own dynamic win probability, with the aggregated odds feed. The gap between your probability and the implied probability from the odds is where value lies. For instance, if your model gives the Braves a 58% chance of winning (implied odds of -138), but the market is offering them at +110 (implied probability of 47.6%), you've identified a potential value bet. This analysis requires a clean, reliable data workflow, not a brittle scraping tool. For analysts managing this synthesis, a tool like PropKit AI frontend data visualization can be instrumental in creating real-time dashboards that compare model probabilities against live market odds, turning data streams into a clear visual decision-making aid.
Stop thinking about bypassing barriers. Start building a professional data stack. Here is a simplified blueprint:
This approach is sustainable, scalable, and sits on the right side of legal and ethical lines. It transforms you from someone trying to sneak data out the back door into a systematic analyst with a reproducible process. The 2024 MLB season saw a record number of data points per game, with an average of over 300 pitches yielding Statcast data. Building a model on that rich, legitimate data is where the real opportunity lies, not in the fleeting numbers on a protected webpage.
References & Further Reading: