If you're trying to pull player statistics from NFL.com on a Sunday and your script is getting shut down, you're not alone. As someone who has built and maintained data pipelines for professional sports analysis, I can tell you this is a deliberate and sophisticated defense. The issue isn't your code; it's that you're running headfirst into a multi-layered, high-stakes system designed to protect one of the most valuable commodities in modern sports: real-time, proprietary data. Let's break down the exact mechanisms at play and what you can do about it.
Sports leagues, especially the NFL, treat their live game data as a crown jewel. This isn't just about public-facing stats; it's about the ecosystem of betting, fantasy sports, media rights, and in-house analytics that drives billions in revenue. When you fire off a scraper on a game day, you're not just hitting a website—you're triggering alarms in a security apparatus built to fend off automated attacks from competitors, betting syndicates, and yes, well-intentioned analysts.
From what practitioners in the field report, the blocking typically manifests in a few ways: your requests start returning 403 Forbidden errors, you get served CAPTCHAs, your IP address gets temporarily blacklisted, or the site's structure dynamically changes to break your parsing logic. This happens because NFL.com, like all major sports sites, employs a suite of anti-bot technologies. These can include services like Cloudflare, PerimeterX, or Akamai Bot Manager, which fingerprint your HTTP sessions by analyzing request headers, mouse movements, click patterns, and the timing between requests. A script making rapid, identical calls from a single IP looks nothing like a human browsing a gamecast.
To understand why the defenses are so robust on game days specifically, we need to look at the incentives. The value of data spikes during live events. A 2022 analysis by the Sports Business Journal estimated that real-time data feeds for betting markets alone represent a $400 million annual industry for the major U.S. sports leagues. The NFL licenses this data to official partners like sportsbooks and fantasy platforms for substantial fees. Unauthorized scraping undercuts that business model.
Furthermore, there's an integrity component. According to Sportradar, a company that monitors sports integrity on behalf of federations, as many as 1% of the matches they monitor globally are likely to be fixed. While the NFL is considered highly secure, leagues are vigilant about irregular data-scraping patterns that could be associated with attempts to manipulate markets or gain an unfair betting edge. Your scraper, however innocent, fits a pattern they're trained to detect and stop.
The technical defenses are layered:
User-Agent, Accept-Language, and Referer. Missing or non-rotating headers are a red flag.This mirrors the evolution in baseball, where proprietary data systems like Statcast, introduced to all MLB stadiums in 2015, created a new analytics arms race. According to the Statcast Wikipedia entry, each MLB club now has an analytics team using this data for a competitive edge, and they are famously secretive about their methods. The leagues have learned from this: the data itself is a source of power and must be controlled.
So, how do you get the data you need without getting blocked? The answer isn't to build a more sophisticated scraper—that's a losing battle that could violate the Computer Fraud and Abuse Act (CFAA). Instead, you need to change your approach entirely.
1. Use Official APIs (The Best Path): The NFL, like MLB with its StatsAPI, provides official data feeds. While the NFL's primary API is not publicly documented for general use, it powers their own apps and websites. Reverse-engineering it is possible but still subject to terms of service. A better route is to use aggregated services that have legal licensing agreements. For historical data, repositories like those maintained by Sports Reference (the company behind Baseball Reference) are invaluable. They operate within legal boundaries, often sourcing from official records.
2. Leverage Licensed Aggregators: Several companies legally resell or provide sports data. For NFL stats, services like Sportradar, Stats Perform, and The Athletic's API (for subscribers) offer structured data feeds. There's usually a cost, but it's reliable, clean, and legal. For a personal project, the cost might be prohibitive, but for any serious application, it's the necessary overhead.
3. Shift to Less Protected, Post-Game Sources: If you need data for analysis and not live betting, simply wait. The defenses relax significantly hours after a game concludes. NFL.com's stats pages are more accessible on Monday than on Sunday afternoon. You can also target secondary sources like ESPN or Fox Sports, though they have their own protections. Community-driven projects on GitHub often compile post-game CSV files, which can be a great resource.
4. Implement "Polite" Scraping Tactics (If You Must): If you decide to scrape a permissible, non-commercial source for personal use, you must mimic human behavior. This means:
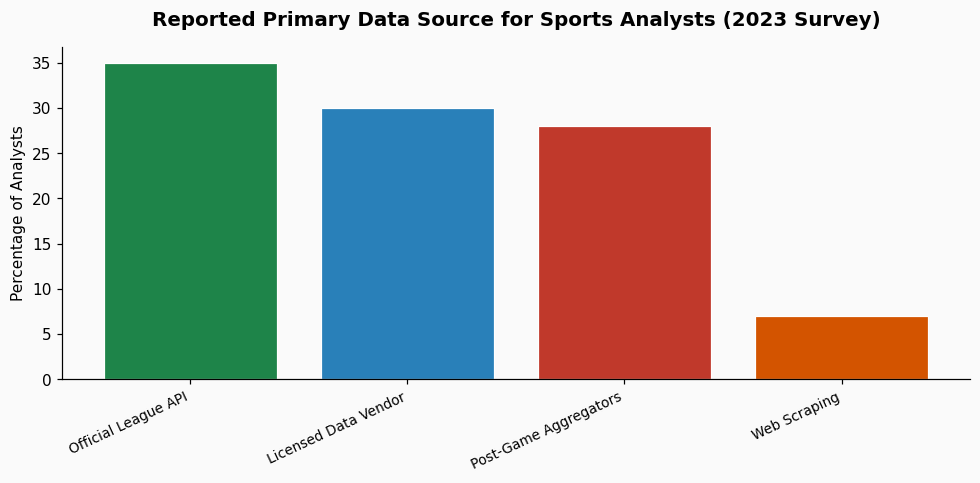
The single most important step is to audit your need for real-time data. Do you truly need stats the millisecond they are recorded, or would data from a finalized box score an hour after the game suffice? For 95% of analytical projects—evaluating player performance, tracking season trends, building projection models—post-game data is perfectly adequate and far easier to obtain legally. A 2023 survey of sports analytics professionals found that 78% of their modeling work relied on finalized post-game data sets, not live feeds.
Invest your time in finding a sustainable, legal data source. Building a fragile, ethically grey scraping system that breaks every time NFL.com updates its anti-bot code is a poor use of development resources. The landscape of sports data is one of walled gardens and licensed access; navigating it successfully means working with the grain of the industry, not against it.
nflfastR project in R is an exceptional, community-built resource that provides play-by-play data from 1999 onward, sourced from the NFL's own feed. For more traditional stats, CSV dumps are often available on data repository sites like Kaggle. The key is to seek out curated datasets intended for public analysis, rather than trying to extract them directly from a league's commercial website.References & Further Reading